A simple interpreter from scratch in Python (part 1)
 RSS feed
RSS feedThe thing that attracted me most to computer science in college was the compiler. I thought it was almost magical how compilers could read even my poorly written source code and generate complicated programs. When I finally took a course in compilers, I found the process to be a lot simpler than I expected.
In this series of articles, I will attempt to capture some of this simplicity by writing an interpreter for a basic imperative language called IMP. The interpreter will be written in Python since it's a simple, widely known language. Python code looks like pseudocode, so even if you don't know Python, you'll be able to understand it. Parsing will be done with a simple set of parser combinators made from scratch (explained in the next article in this series). No external libraries will be used except for sys (for I/O), re (for regular expressions in the lexer), and unittest (to make sure everything works).
The IMP language
Before we start writing, let's discuss the language we'll be interpreting. IMP is a minimal imperative language with the following constructs:
Assignment statements (all variables are global and can only store integers):
x := 1
Conditional statements:
if x = 1 then y := 2 else y := 3 end
While loops:
while x < 10 do x := x + 1 end
Compound statements (separated by semicolons):
x := 1; y := 2
Okay, so it's just a toy language, but you could easily extend it to be something more useful like Lua or Python. I wanted to keep things as simple as possible for this tutorial.
Here's an example of a program which computes a factorial:
n := 5; p := 1; while n > 0 do p := p * n; n := n - 1 end
IMP provides no way to read input, so the initial state must be set with a series of assignment statements at the beginning of the program. There is also no way to print results, so the interpreter will print the values of all variables at the end of the program.
Structure of the interpreter
The core of the interpreter is the intermediate representation (IR). This is how we represent IMP programs in memory. Since IMP is such a simple language, the intermediate representation will correspond directly to the syntax of the language; there will be a class for each kind of expression or statement. In a more complicated language, you would want not only a syntactic representation but also a semantic representation which is easier to analyze or execute.
The interpreter will execute in three stages:
- Split characters in the source code into tokens
- Organize the tokens into an abstract syntax tree (AST). The AST is our intermediate representation.
- Evaluate the AST and print the state at the end
The process of splitting characters into tokens is called lexing and is performed by a lexer. Tokens are short, easily digestible strings that contain the most basic parts of the program such as numbers, identifiers, keywords, and operators. The lexer will drop whitespace and comments, since they are ignored by the interpreter.
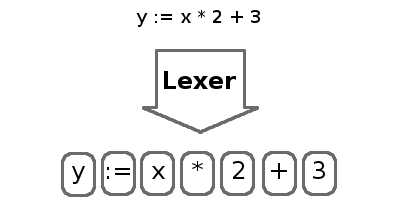
The process of organizing tokens into an abstract syntax tree (AST) is called parsing. The parser extracts the structure of the program into a form we can evaluate.
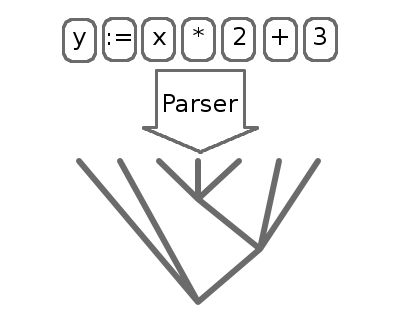
The process of actually executing the parsed AST is called evaluation. This is actually the simplest part of the interpreter.
This article will focus solely on the lexer. We will write a generic lexer library, then use it to create a lexer for IMP. The next articles will focus on the parser and the evaluator.
The lexer library
The operation of the lexer is fairly simple. It is heavily based on regular expressions, so if you're not familiar with them, you might want to read up. In short, a regular expression is a specially formatted string that describes other strings. You can use them to match strings like phone numbers or e-mail addresses, or in our case, different kinds of tokens.
The input to the lexer will be just a stream of characters. To keep things simple, we will read an entire input file into memory. The output will be a list of tokens. Each token comprises a value (the string it represents) and a tag (to indicate what kind of token it is). The parser will use both to decide how to create the AST.
Since the operation of a lexer for any language is pretty similar, we will create a generic lexer which takes a list of regular expressions and corresponding tags. For each expression, it will check whether the input text matches at the current position. If a match is found, the matching text is extracted into a token, along with the regular expression's tag. If the regular expression has no tag associated with it, the text is discarded. This lets us get rid of junk characters, like comments and whitespace. If there is no matching regular expression, we report an error and quit. This process is repeated until there are no more characters left to match.
Here is the code from the lexer library:
import sys
import re
def lex(characters, token_exprs):
pos = 0
tokens = []
while pos < len(characters):
match = None
for token_expr in token_exprs:
pattern, tag = token_expr
regex = re.compile(pattern)
match = regex.match(characters, pos)
if match:
text = match.group(0)
if tag:
token = (text, tag)
tokens.append(token)
break
if not match:
sys.stderr.write('Illegal character: %s\\n' % characters[pos])
sys.exit(1)
else:
pos = match.end(0)
return tokens
Note that the order we pass in the regular expressions is significant. lex will iterate over the expressions and will accept the first one that matches. This means, when using lex, we should put the most specific expressions first (like those matching operators and keywords), followed by the more general expressions (like those for identifiers and numbers).
The IMP lexer
Given the lex function above, defining a lexer for IMP is very simple. The first thing we do is define a series of tags for our tokens. IMP only needs three tags. RESERVED indicates a reserved word or operator. INT indicates a literal integer. ID is for identifiers.
import lexer RESERVED = 'RESERVED' INT = 'INT' ID = 'ID'
Next we define the token expressions that will be used in the lexer. The first two expressions match whitespace and comments. These have no tag, so lex will drop any characters that they match.
token_exprs = [
(r'[ \n\t]+', None),
(r'#[^\n]*', None),
After that, we have all our operators and reserved words. Remember, the "r" before each regular expression means the string is "raw"; Python will not handle any escape characters. This allows us to include backslashes in the strings, which are used by the regular expression engine to escape operators like "+" and "*".
(r'\:=', RESERVED),
(r'\(', RESERVED),
(r'\)', RESERVED),
(r';', RESERVED),
(r'\+', RESERVED),
(r'-', RESERVED),
(r'\*', RESERVED),
(r'/', RESERVED),
(r'<=', RESERVED),
(r'<', RESERVED),
(r'>=', RESERVED),
(r'>', RESERVED),
(r'=', RESERVED),
(r'!=', RESERVED),
(r'and', RESERVED),
(r'or', RESERVED),
(r'not', RESERVED),
(r'if', RESERVED),
(r'then', RESERVED),
(r'else', RESERVED),
(r'while', RESERVED),
(r'do', RESERVED),
(r'end', RESERVED),
Finally, we have expressions for integers and identifiers. Note that the regular expression for identifiers would match all of the reserved words above, so it is important that this comes last.
(r'[0-9]+', INT),
(r'[A-Za-z][A-Za-z0-9_]*', ID),
]
Now that our regular expressions are defined, we need to create an actual lexer function.
def imp_lex(characters):
return lexer.lex(characters, token_exprs)
If you're curious to try this, here's some driver code to test it out:
import sys
from imp_lexer import *
if __name__ == '__main__':
filename = sys.argv[1]
file = open(filename)
characters = file.read()
file.close()
tokens = imp_lex(characters)
for token in tokens:
print token
To be continued...
In the next article in the series, I'll discuss parser combinators and describe how to use them to build an abstract syntax tree from the list of tokens generated by the lexer.
If you're curious to try out the IMP interpreter, you can download the full source code.
To run the interpreter on the included sample file:
python imp.py hello.imp
To run the included unit tests:
python test.py