Error handling guidelines for Go
 RSS feed
RSS feedError handling is one of the most ambiguous parts of programming. There are many ways to do it. One approach is usually better than others, but it's not always clear what that is, especially in a new language or environment.
Error handling has been on my mind a lot lately, working on gorelease and other Go command line tools. I thought I would collect some advice and rules of thumb for error handling here in case it's useful for anyone else.
When to return errors
A function may indicate an error in three ways: by returning a sentinel value (like nil, false, or -1), by returning an error value, or by panicking.
A function should return a sentinel value if its purpose is to find or check something in its input. For example, strings.Index returns -1 if its substring is not found; regexp.Regexp.Find returns nil. These aren't actually errors. The caller is allowed to pass in a string that doesn't contain a substring. That might be the whole reason the caller is using the function.
A sentinel value may have the same type as a successful return value, but it must be outside the normal range. For example, strings.Index can return -1 because string indexes can't be negative. If this doesn't make sense for your function or if you want to make usage more obvious to the caller, it may be better to return a separate ok bool value.
A function should return an error if it might encounter a problem with an input that its caller can't anticipate, or if it might encounter an error with an outside system (like the network), or if it calls another function that returns an error. For example, strconv.ParseInt returns an error if its string argument can't be parsed as an integer: the caller can't anticipate that without calling ParseInt. io/ioutil.ReadFile returns an error if it can't read a file: the file system is unpredictable, and a lot of things could go wrong.
By convention, the error should be the last value returned by the function. It should have type error, not a specific defined type: more types of errors might be needed in the future.
A function should panic if it's called in an invalid situation or if it's called with inputs outside its domain. For example, sync.Mutex.Unlock panics if Lock wasn't called first. io.Copy panics when called with nil arguments. nil is not forbidden by the type system, but it's not a valid argument for many functions.
A good way to think about this is design by contract. Each function has a contract with the rest of the program specified by its name, documentation, and type signature. Given inputs satisfying some preconditions, it will return outputs satisfying some postconditions. If the contract is violated, the program has a bug, and the function may do something unexpected (like panicking).
By convention, it's unusual to call panic explicitly in Go, but it's also good to fail as early as possible when a problem is detected. For example, a function that stores its input in a long-lived data structure should panic if its input isn't valid rather than risking a crash much later.
When in doubt, return an error, especially when designing an API that will be difficult to change later. Changing a function that returns an error into one that panics or returns a sentinel value (a special error) is easy; going to other direction requires an incompatible API change.
Error messages
Error messages are part of a program's user interface, so a good error message should be concise and understandable to the user, not just the programmer. An error message should not mention implementation details like function or variable names and should not include the call stack. It's fine to include implementation details in panic messages, since those are mainly useful to programmers. It's also fine to include details in logs and reports; some bugs are very difficult to fix without them.
Good error messages communicate three things: what went wrong, why it went wrong, and what can be done to fix it. These don't have to be three separate sentences, and it's not always possible to know what went wrong or what the user should do, but try your best. For example, take a look at the Firefox error page below:
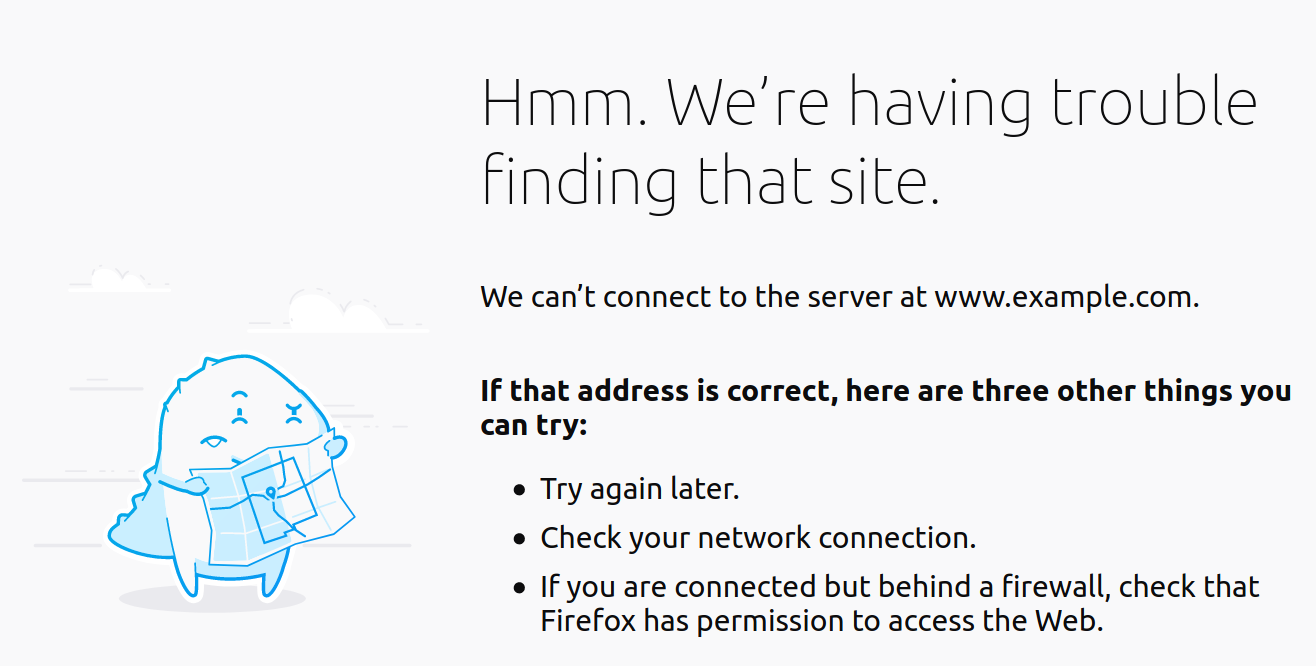
The audience matters a lot when writing error messages. Users of command line tools tend to be more technical, and space in the terminal is limited, so error messages should be short and should leave out anything obvious. For example, if a program fails to write a file because the disk is full, there's no need to tell the user to delete files or empty the trash.
Context and wrapping
In Go, when a function returns an error, it's common for the calling function to add more context by wrapping the error. There are a few ways to do this, but using the %w verb with fmt.Errorf is the simplest.
if err := ioutil.WriteFile("config.json", data, 0666); err != nil { return fmt.Errorf("writing configuration: %w", err) }
Error messages should include relevant arguments and local variables to provide context to the user. To avoid redundancy when wrapping errors, each function is responsible for including its own values in the error message, except for arguments passed to the function that returned the wrapped error. In the example above, io/ioutil.WriteFile returns an *os.PathError that includes the string "config.json". The caller should not also mention "config.json".
Rather than say more about this, I'll link to Bryan Mills's experience report on this topic, which goes into a lot more depth. We worked together last year on eliminating redundancy from the go command's error messages. Before that, it was common to see an import path repeated three or four times in a go build error message.
Instead, I'll show you a cool trick. If a function calls several other functions that return errors, and it needs to wrap all the errors the same way, you can wrap them with a deferred function that assigns to a named return value, err.
func writeConfig(data *config) (err error) { defer func() { if err != nil { err = fmt.Errorf("writing configuration: %w", err) } }() b, err := json.Marshal(data) if err != nil { return err } if err := return ioutil.WriteFile("config.json", b); err != nil { return err } return nil }
Error types
A type can be used as an error if it has an Error method that returns a string.
type ImportError struct { Path string Err error } func (e *ImportError) Error() string { return fmt.Sprintf("could not import %s: %v", e.Path, e.Err) } func (e *ImportError) Unwrap() error { return e.Err }
There are several situations where you might want to define an error type:
- Callers of your function need to handle some kinds of errors differently than others. For example,
go/build.ImportDirreturns a*build.NoGoErrorif the directory doesn't contain a Go package. Tools may wish to skip the directory instead of reporting a fatal error. - The error carries information that is useful outside of the error message. This may be useful when recovering from the error or when presenting the error to the user. For example,
os.PathErrorincludes a file name.golang.org/x/mod/module.ModuleErrorincludes a module path and version. - The same error is returned from many places and should have a consistent message.
If none of these situations apply, there's no harm in using fmt.Errorf.
When you define an error type, try to follow these conventions:
- The type name should end with
Error(like the examples above). - Sentinel error variable names should begin with
Errorerr(likeos.ErrNotExist). - If an error struct type wraps another error, the field containing the wrapped error should be named
Errerr(Errorwould conflict with the method of the same name). - Wrapping error types must define an
Unwrapmethod. - Prefer using pointer receiver types for error methods. Most error types can use either pointer or value receiver types, but it's easy for programmers if they don't have to look up whether to use a pointer when returning an error.
When you're testing whether an error has a certain type, use errors.As instead of using a type assertion. This checks not only the error itself but also any errors it wraps. You may also want to use a predicate provided by the library defining the error like os.IsNotExist.
if nogoErr := (*build.NoGoError)(nil); errors.As(err, &nogoErr) { ... }
One last piece of advice: in a public API, prefer defining an error type over defining a sentinel error variable. It's common to add contextual information to an error later on, and it's much easier to do that with an error type.