Polymorphic Inline Caches explained
 RSS feed
RSS feedI'm moving to a new team at work where I'll be optimizing the V8 Javascript JIT compiler for Android. To prepare for this new role, I've been reading a lot of research papers on JIT compilation since I've mainly worked with static, compiled languages in the past. There are some pretty cool things you can accomplish when you're generating native code on the fly. Most of them stem from the fact that you don't have to generate code just once: you can rewrite and recompile code at any time using runtime information.
A particularly clever example of this is the Polymorphic Inline Cache. As presented by Urs Hölzle in Optimizing Dynamically-Typed Object-Oriented Languages With Polymorphic Inline Caches [PDF], PICs are a way to optimize polymorphic function calls in dynamic languages.
Let's say we have the following polymorphic function call. How would we compile it normally in a JITed language?
function feed(animal, food) {
...
animal.munch(food);
...
}
We don't have any type information about animal, so we can't call the munch method directly. We have to look it up. If we were compiling code in a statically typed language, we would probably do a vtable lookup, which is fairly fast. However, in a dynamically typed language, there may be many classes with a munch method with no inheritance relationship, so it's impossible to know a vtable offset ahead of time. So we are forced to do a hash table lookup and probably a string comparison.
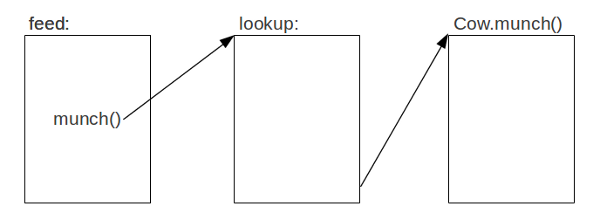
Most call sites actually only deal with one class though. This is called a monomorphic call site. At these sites, we should only have to look up the method only once. Since we can dynamically rewrite JITed code, we can just have the lookup function rewrite the call as a direct call to the target method.
This would work perfectly if we could guarantee objects of another class would not be used at the same call site later. No such guarantee is generally possible though, so we have to add some code which makes sure the target object is of the correct class. If it's not, we fall back to calling the lookup function. This type checking code can be inserted at the beginning of every method which may be called polymorphically. We can save memory by adding the checking code per method rather than per call site, since, in general, there ought to be fewer methods than call sites.

This works well for monomorphic call sites, but what about call sites that actually call methods in multiple classes? These are true polymorphic call sites. Polymorphic inline caches are meant to optimize this kind of call.
When we detect a "cache miss" from a monomorphic call site, i.e., the type check fails in a method, we create a stub function, which compares the target object's class against a small number of previously used (cached) classes. If it finds a match, it calls the corresponding method directly. If not, it calls the lookup function, which will add a new entry to the stub. The original call site is rewritten to call the stub directly.
Note that when we call a method from a stub, we already know we have the right class, so we can skip the type checking code at the beginning of the target method.
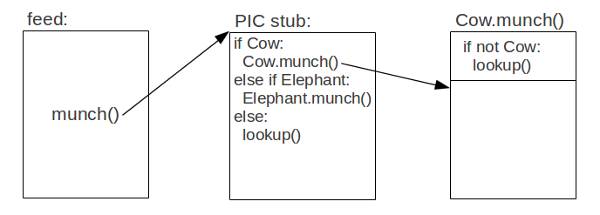
What about call sites which call methods on lots of different classes? Maybe the feed() function is used as part of a zoo simulator, and it's called for hundreds of different species. These are called megamorphic call sites, and PICs don't really make sense for these. Looking up a method in a megamorphic PIC would be even slower than just looking it up in a hash table, so it's best to limit the size of each PIC to a small number of entries.
Megamorphic call sites are pretty rare though, and PICs are useful most of the time. We can even do some additional optimizations once a PIC has been called enough times to be stable. We can rewrite the calling routine to inline the entire PIC. This won't use any extra memory since we have at most one PIC per call site anyway. Also, if we find one class is being used more than others, and the target method is short enough, we can even inline the method itself.
This kind of inlining is not possible in an ahead-of-time compiler without some elaborate profile guided optimization. You can't inline a polymorphic function call, since you don't know, statically, which method should actually be called. Inlining is a really important optimization, too, since it not only eliminates function call overhead but also enables other optimizations, such as improved instruction scheduling. So this is actually a case where JIT compiled code has the potential to outperform ahead-of-time compiled code.