A tale of two benchmarks
 RSS feed
RSS feedGood benchmarks are extremely useful tools for software developers. They tell you the weaknesses of your hardware and software, so you know what to optimize. Customers also care about them a lot, and higher benchmark scores mean more sales.
What is a benchmark anyway?
A benchmark is a suite of tests which measures the performance of a computing system. "Performance" usually means speed, but it can also mean memory usage, network bandwidth, disk latency, or any number of things. "Computing system" means everything the benchmark runs on. For a benchmark that tests JavaScript performance, the computing system would include the JavaScript virtual machine, the web browser, the operating system, the compiler used to build everything, and the hardware.
Usually, benchmarks focus on a specific area, like how many fish your web browser can draw per second, how many triangles your GPU can render, or how good your compiler is at optimization. Within that area, a good benchmark will have many different tests which represent various real-world tasks. It's really important that tests represent real-world tasks or you will end up optimizing something that doesn't matter. It's also important that tests cover many real-world scenarios so you don't miss optimizing something important.
Benchmarking Methodology
Let's pretend we're creating a new benchmark. We'll assume we are measuring speed and that we've already written a suite of tests which represent a broad set of real-world scenarios. Our challenge is to use these tests to come up with information that is useful for comparing performance on different platforms.
There are two basic ways to measure speed: we could measure how long it takes to do a certain amount of work (i.e., how long it takes to run a test 10 times), or we could measure how much work we can get done in a certain amount of time (i.e., how many times can we run each test in 10 seconds). These are both good approaches, and they effectively measure the same thing (work per time is the reciprocal of time per work). I tend to prefer the second approach, since higher scores (more iterations) are better, which is intuitive. It also puts an upper bound on how long the benchmark will run, which is useful on slow platforms.
In both cases, you'll want to run each test for a minimum number of iterations and find the mean time per iteration. This will reduce the impact of "random" events like garbage collection pauses or OS task switching. You should also strive to make each iteration of a test as consistent as possible. For example, if you are trying to measure garbage collector performance, but the garbage collector only kicks in every 10 iterations, you would measure a large difference between a system that runs 19 iterations and a system that runs 20 iterations, even though the actual difference is very small.
Once you have average scores for all tests in your benchmark, you need a way to compare them with scores on other platforms. The best way to do this is to pick a "reference" score, and divide by that. This is called normalization, and it's really important. Let's say your company releases its first product, and it runs 200 iterations of FooTest in 10 seconds. When you release version 2.0 the following year, it can run 300 iterations of FooTest. You want to tell your customers "version 2.0 is 50% better at Foo!" You don't want to say "version 2.0 is 100 iterations better at FooTest." That's not meaningful since it depends on how the test was written; if you had written FooTest so it did twice as much work per iteration, you would be saying "50 iterations better", even though the same amount of work would be done per second.
You also need a way to combine scores from individual tests into one grand total score. If your test scores are normalized, i.e., you divided by a reference score, each score is a ratio. In order to get a total score, you must not add them together or use the arithmetic mean. This will give you meaningless results. Instead, use the geometric mean. The geometric mean is the nth root of the product of n ratios:
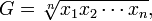
The geometric mean is intended for averaging ratios (normalized data). If you don't believe me on this, I recommend you read How not to lie with statistics: The correct way to summarize benchmark results [PDF] by Fleming Wallace. Note that it's not meaningful to use the geometric mean on raw, non-normalized data. Don't bother summarizing raw data without normalizing it.
V8 gets it right
V8 is the JavaScript engine found in Google Chrome and Android. The authors of V8 came up with the V8 Benchmark Suite. After all, what better way is there to show that you have the best JavaScript engine than to invent your own benchmark (at which you excel), and then tell everyone that the other benchmarks are buggy and irrelevant?
Seriously though, the V8 benchmark suite gets it pretty much right. It comprises seven tests representing various computationally intensive things that you might want to do with JavaScript (cryptography, ray tracing, regular expressions, etc). Each test is run for a few seconds for as many iterations as possible. If a test hasn't performed a minimum number of iterations, it keeps running until it does. Test scores are normalized to reference values and combined with the geometric mean.
There is one test in V8, which is unfortunately very inconsistent. Splay measures garbage collector performance by building a large data structure, then repeatedly adding and removing small parts of it. Usually, garbage collectors kick in after a certain amount of memory has been allocated, but this amount varies a lot. The amount of time taken by the garbage collector depends not only on the implementation (what we want to measure) but also the current state of the heap (which depends on earlier tests, what other tabs you have open, what you have in the cache, etc). The time taken for a collection cycle can vary by orders of magnitude depending on whether the whole heap is collected or only the young generation. To make matters worse, the garbage collector usually won't run at all on most iterations of Splay. Whether you get a good score on Splay is largely a matter of luck.
SunSpider gets it wrong
SunSpider is one of the older JavaScript benchmarks, but it's still widely used to compare web browser performance. It's developed and maintained by the WebKit team.
The first thing you'll notice about SunSpider is that it runs really quickly. On my desktop, most tests complete in less than 10 ms. Since JavaScript can only measure time with a resolution of 1 ms, this gives really noisy results. If a test runs in 5 ms in one iteration and 6 ms in the next, is there really a 20% difference in performance? Or was it actually 5.99 ms and 6.02 ms?
SunSpider also doesn't normalize scores for each test. It just runs each test for a fixed number of iterations, takes the average running time for each test, then adds the averages together. If you look at the results, it should be obvious why normalization is so important and why adding raw data together is wrong. On my desktop, bitops-3bits-in-byte runs in 0.8 ms on average, but access-fannkuch runs in 16.2 ms. That means, from an optimization perspective, that access-fannkuch is 20.25 times as important bitops-3bits-in-byte. Even if you made bitops-bits-in-byte run infinitely fast (in 0 ms), you would only reduce your SunSpider score by 0.5%. This is the wrong conclusion. Bit operations in general may be just as important as access operations, but the benchmark suite doesn't tell us that.
SunSpider has some other weird quirks as well. It has two identical copies of each test. Both copies are run, but only times from the second copy are recorded. Each test is loaded in a fresh iframe. Also, tests are run in interleaved order (ABCABC rather than AAABBBCCC). I think these last two factors are intended to simulate page loads and prevent the JavaScript engine from warming up to get good performance on each test.
Conclusion
Benchmarks are a critical tool for measuring performance. Developers use them to determine what areas of a system need the most optimization. Because of they way benchmarks are used, it is crucial that they accurately reflect real world performance so that optimizations actually improve user experience.